
ATS Keywords for Data Scientists & ML Engineers (and What's Changed in 2026)
We see it all the time. A strong data scientist got passed over, and the resume wasn't the problem. The wording was.
One case stuck with us. A candidate had built a fraud model that saved their company over ten million dollars a year. Real work. They didn't make the shortlist. Why? Their resume said "tree-based ensembles." The recruiter searched for "XGBoost." Same skill, two words for it, and the better engineer never came up.
This happens in data and ML more than almost anywhere else. The vocabulary is huge and oddly literal. Half of it is abbreviations that software reads as different words. So treat this as a translation guide: how your work gets described versus how the job describes it. Which terms still matter in 2026, how to group them, and why "just add more keywords" is now only half the story.
Two filters now, not one
The old filter hasn't gone anywhere. Your formatted file gets stripped to plain text. A recruiter searches that text for exact words. Miss the word, miss the result. Blunt, but that's how it works.
The new filter sits on top. Plenty of teams now run a semantic or AI pass before a human looks at it. And recruiters often skim with an AI summary open beside the resume. That layer reads meaning. "Built the personalisation engine" can register against a "recommender systems" line even when the words don't match.
This splits the old advice into two:
- The literal layer still wants the right terms, spelled the posting's way.
- The meaning layer now punishes padding. A skills section that's just a pile of tool names looks like filler to the model — and lazy to the human reading after it.
So the lists below aren't a target to max out. They're a reminder. If it's true of you, say it in plain words, and tie it to something you shipped.
The acronym trap
Small thing, but it sinks good people. Search doesn't expand abbreviations the way your brain does. You read "NLP" and "natural language processing" as one idea. A keyword query sees two unrelated strings. The job wrote one, you wrote the other — no match.
Fixing it costs nothing. Write it both ways once: "natural language processing (NLP)." Then use whichever form the posting uses. Same for ML, RAG, K8s, EDA.
The keywords, by category
Start from the posting. It decides which of these belong on your resume. Add only what's genuinely true.
- Modelling & method. Cover the families you've actually worked in — predicting categories versus numbers (classification, regression), grouping things (clustering), and the specialisms: language work (NLP), vision, recommenders and ranking, anomaly detection, forecasting over time, reinforcement learning. Round it out with the craft terms recruiters type into the box: feature engineering, validating with cross-validation, tuning hyperparameters, how you evaluated the model.
- Algorithms. These get searched by name, so name the ones you used. Regression in both flavours, tree models from a single decision tree up to random forests, and the boosting family — XGBoost as the usual default, LightGBM when speed matters, CatBoost for categorical-heavy data. Then neural nets where they apply (convolutional for images, recurrent and LSTM for sequences), transformers and attention, embeddings, graph neural networks.
- Frameworks & libraries. Write the exact name — literal matching is harshest here. Deep-learning work usually means PyTorch or TensorFlow (Keras or JAX too); classic ML leans on scikit-learn and XGBoost; language work pulls in Hugging Face and spaCy. The everyday stack is pandas, NumPy and SciPy, and put your experiment tracker on there too — MLflow, Weights & Biases, a notebook in Jupyter.
- Languages. Python comes first; it's the single most-searched term in the field. Then SQL, with the dialect if it earns the space (PostgreSQL, BigQuery). R, Scala or Bash only where you genuinely used them.
- Data & pipelines. Increasingly expected even on "scientist" roles: moving and shaping data (ETL/ELT, pipelines), the big-data tools (Spark and PySpark, Hadoop, Databricks), orchestration through Airflow or dbt, streaming with Kafka, and a warehouse — Snowflake, BigQuery or Redshift.
- Cloud & MLOps. Often the line between "interesting" and "hire." Name your cloud (AWS, GCP or Azure) and its ML service (SageMaker, Vertex AI, Azure ML), how you packaged and ran things (Docker, Kubernetes), and the operational side: deployment, monitoring, CI/CD, feature stores, Terraform, Git.
- Statistics & experimentation. What separates product-minded scientists from model-tinkerers: hypothesis testing and A/B testing, designing experiments, causal inference, a little Bayesian thinking, and the exploratory data analysis everyone searches for and nobody brags about.
Paste a real posting into a checker and the gap stops being theoretical. You see it laid out — what you've covered, and what you haven't:
📷 [СКРИН 1 — keyword map: score 50.1 + matched/missing]
Green is what your resume already says. Red is what the job wants and yours doesn't mention yet.

GenAI isn't a bonus line anymore
A year and a half ago, "experimented with LLMs" could sit at the bottom and pass for forward-thinking. Not now. In 2026 it's one of the first things a screener looks for — and not only on roles with "LLM" in the title. If you've shipped anything here, put it near the top.
The terms worth naming, if they're true of you: the models themselves (large language models, generative AI), the retrieval pattern everyone wants now (RAG), and how you adapted a model — full fine-tuning, or the lighter LoRA and PEFT — plus prompt engineering. On the infrastructure side, that's embeddings and vector search, a vector store of some kind (Pinecone, Weaviate, FAISS or pgvector), orchestration through LangChain or LlamaIndex, and anything agentic, including how you evaluated it.
Built a RAG pipeline that actually answered support tickets? Wrote an eval harness that caught a regression before launch? That's a headline. Not a footnote.
Lead with the cluster that fits the title
The same person reads as five different searches depending on the role. Put the matching cluster up front:
- Data Scientist — statistics, A/B testing, modelling, Python and SQL, business impact.
- ML Engineer — production ML, MLOps, deployment, Docker/Kubernetes, cloud, pipelines.
- Data Analyst — SQL, dashboards (Tableau, Power BI), reporting, EDA, business metrics.
- MLOps / Platform — Kubernetes, CI/CD, model serving, monitoring, feature stores, Terraform.
- NLP / LLM Engineer — transformers, Hugging Face, RAG, fine-tuning, vector databases.
What one rewrite actually does
Same achievement, written two ways.
Built models to improve customer retention.
Shipped a LightGBM lead-scoring model in Python, served on Vertex AI behind a dbt and Airflow pipeline, lifting sales-qualified leads 23%.
The second one names four searchable terms — algorithm, language, cloud service, orchestrator. It still reads like a human wrote it. And it ends on a number. Found by the machine, believed by the recruiter. Do that across six bullets and the resume becomes a different document.
Find your gaps in two minutes
You don't have to guess. Drop your resume and a target posting into our free ATS resume checker. It pulls the important terms out of the job. It marks which ones are already in your resume and which aren't. And it scores the match.
It's synonym-aware for this field, too. "sklearn" counts as "scikit-learn." "NLP" counts as "natural language processing." So you get an honest read, not a string-match gotcha.
It also shows the plain text an ATS pulls from your file. That matters more than keywords if a fancy template is scrambling your resume before any search even runs (more on that here):
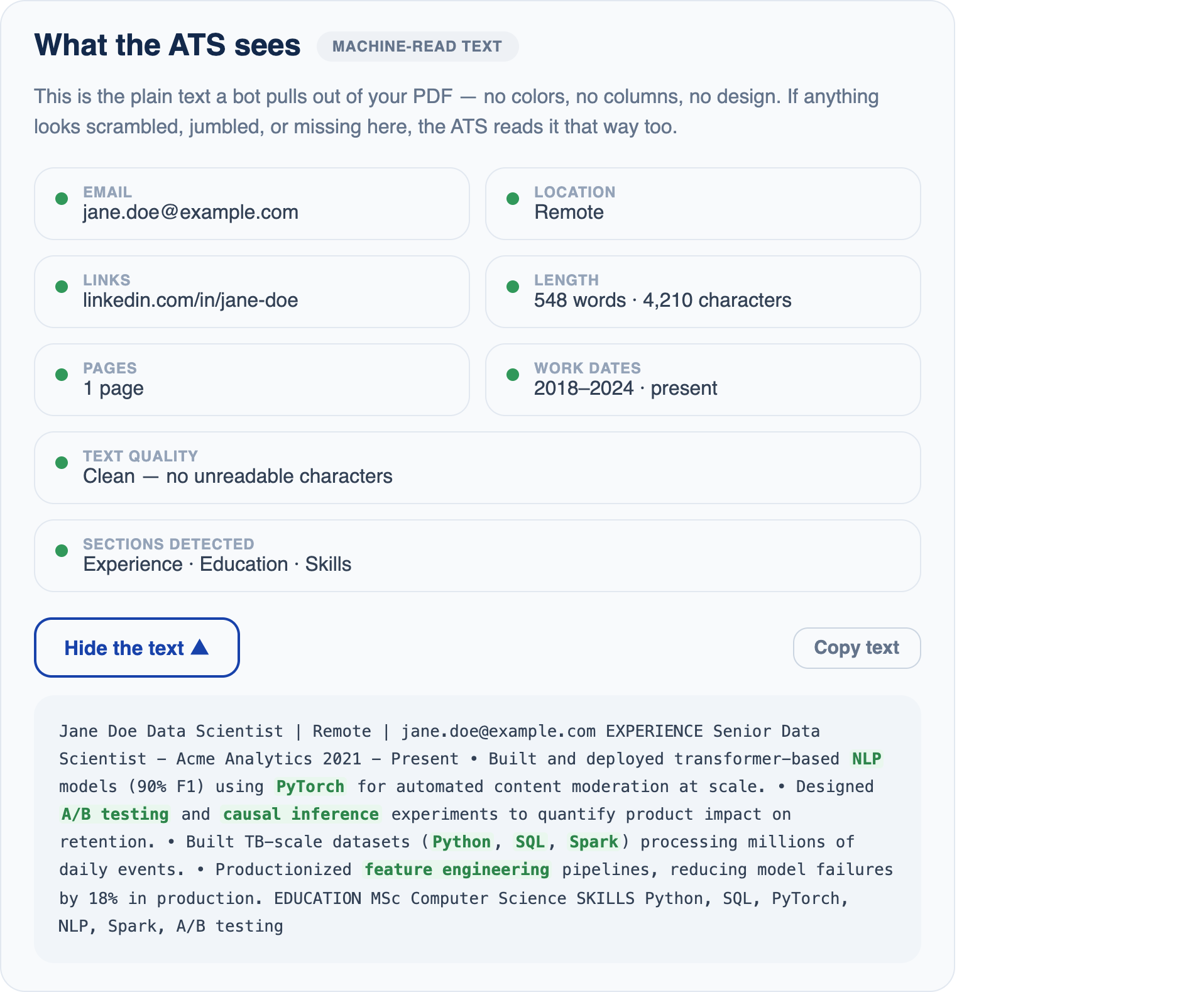
The raw text an ATS reads, with contact details, sections and matched keywords pulled out. If your name or skills are missing here, fix the file first.
For every gap, it also gives you a fix and a fill-in-the-blanks example line. The placeholders are left in on purpose, so the numbers stay yours:

Prioritised fixes with example bullets to adapt — the quickest route from "missing keyword" to an actual resume line.
Run it, add back the terms that are genuinely true of you, and re-check until the red shrinks.
A few things not to do
- Don't pad. A keyword soup gets demoted by the AI layer and dismissed by the human. Earn each term inside a real bullet.
- Don't claim what you can't defend. Every keyword is a possible interview question, and ML screens aren't gentle.
- Don't bury your numbers. Terms get you found. Results get you hired. You need both.
- Don't write to a template. Write to the posting. It's the best keyword source you'll get.
Quick answers
Which ATS keywords matter most for a data scientist? Python, SQL, machine learning, statistics, and A/B testing — plus the exact frameworks and cloud tools named in the posting. Add GenAI and LLM terms if your work touches them. Tailor every time.
Do keywords still matter now that companies use AI screening? Yes. The literal search hasn't gone away, and recruiters still skim. The AI layer just raises the bar on context and results on top of the keywords. It doesn't replace them.
Should I spell out NLP, ML and the rest? Both forms, at least once. Search is often literal.
Are keywords enough to land an interview? No. They clear the filters and get you found. Quantified impact and a real fit get you shortlisted.
Put the skills you actually have into the words the job uses, and back them with numbers. Then the filters stop working against you. Before your next application, see which keywords you're missing — free, no sign-up.
Looking for your next role in data or ML? Join Hiretop's talent network and get matched with real engineering jobs.