Datacurve’s Innovative Approach to LLM Training
In the expansive landscape of artificial intelligence, the journey towards refining and advancing Language Models (LMs) is akin to charting unexplored territories—a continuous odyssey marked by innovation, breakthroughs, and relentless pursuit of excellence. Amidst this dynamic landscape, Datacurve emerges as a guiding light, a trailblazing startup founded in the fertile soil of 2024 by the visionary trio of Serena Ge, Charley Lee, and steered by the seasoned guidance of Group Partner Garry Tan. Their venture is not merely a venture but a mission—a mission rooted in the core belief of delivering expert-quality data at an unprecedented scale to propel the evolution of Large Language Models (LLMs) to new heights.
Datacurve's inception heralds a new era in AI development—a time where the demand for cutting-edge capabilities transcends mere expectation and delves into the realm of necessity. But what makes Datacurve a harbinger of change? What sets it apart in a sea of startups vying for recognition and impact? To unravel these questions, one must delve deeper into the essence of Datacurve's vision and strategy.
Challenges in LLM Training: Unveiling the Complexities
Embarking on the quest to enhance LLM capabilities is akin to navigating a labyrinth—a labyrinth fraught with challenges, each presenting formidable hurdles that demand meticulous navigation and strategic solutions. Serena and Charley, drawing from their reservoir of knowledge in software development and AI, have meticulously dissected the multifaceted challenges plaguing LLM training:
Scalability: The Everest of Data Acquisition
Scaling the heights of high-quality code data acquisition proves to be a Herculean task—a daunting ascent riddled with treacherous pitfalls and unforeseen obstacles. In a realm where synthetic generation and scraping techniques often falter in capturing the nuanced intricacies of real-world coding scenarios, the pursuit of scalability emerges as a formidable challenge. The repercussions of suboptimal training outcomes loom large, casting a shadow over the efficacy and reliability of LLMs.
Talent Acquisition: Navigating the Talent Terrain
In the vast expanse of talent acquisition for manual data labeling, Serena and Charley find themselves traversing uncharted territories fraught with uncertainty and ambiguity. The gig economy landscape, with its siren call of low-skilled labor, poses a formidable challenge—a challenge exacerbated by the scarcity of skilled human annotators capable of producing top-tier annotated data sets. Assembling a team endowed with the requisite expertise and passion becomes a quest in itself—a quest for the proverbial needle in a haystack amidst a sea of mediocrity.
As Datacurve embarks on its transformative journey, these challenges serve as catalysts for innovation, driving the team to push the boundaries of conventional wisdom and redefine the paradigm of LLM training.
Datacurve: Revolutionizing LLM Training with Innovative Data Curation
As Datacurve sets sail on its transformative journey, it endeavors not merely to tread the beaten path but to chart new territories, redefine norms, and revolutionize the very fabric of LLM training. At the heart of this audacious endeavor lies a commitment to innovation—a commitment manifested through its groundbreaking approach to data curation. Central to Datacurve's vision is the development of a gamified annotation platform—a platform meticulously crafted to transcend the confines of traditional data annotation methodologies and usher in a new era of engagement, collaboration, and excellence. But what makes Datacurve's approach truly groundbreaking? How does it promise to surmount the myriad challenges plaguing LLM training and pave the way for unprecedented advancements?
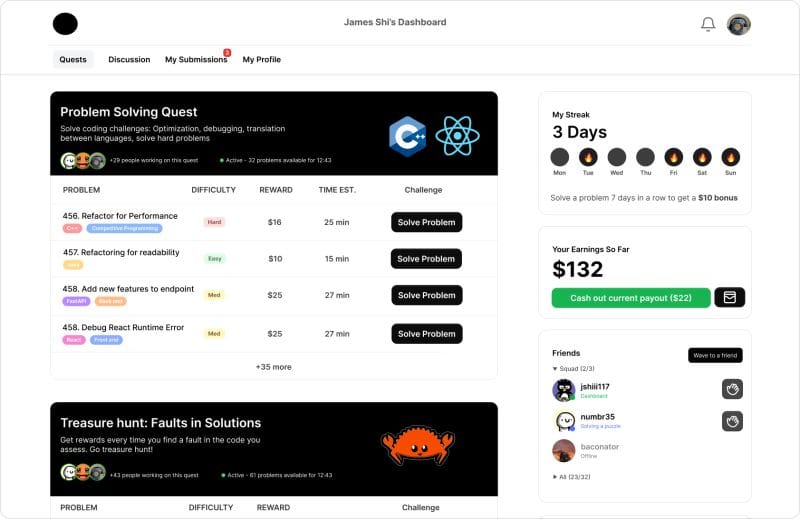
The Gamified Annotation Platform: Catalyzing Innovation
Datacurve's gamified annotation platform stands as a testament to the power of innovation—a beacon of ingenuity amidst the sea of conventional practices. By seamlessly integrating elements of gamification into the data annotation process, Datacurve transcends the mundane, transforming what was once perceived as a monotonous task into an immersive and exhilarating experience. Engineers, drawn by the allure of stimulating coding challenges and the promise of tangible rewards, find themselves propelled into a world where learning, collaboration, and competition converge harmoniously. The platform serves not merely as a tool for data annotation but as an engine of innovation—a crucible where ideas are forged, refined, and brought to fruition.
Unraveling the Gamification Paradigm
At the core of Datacurve's gamified annotation platform lies a sophisticated framework designed to incentivize participation and foster a sense of community among its users. Through a carefully curated system of challenges, achievements, and rewards, Datacurve empowers engineers to unleash their full potential, transcending perceived limitations and embracing the spirit of exploration. Whether tackling complex coding puzzles, collaborating with peers on shared projects, or competing in friendly competitions, participants find themselves immersed in an ecosystem where learning becomes synonymous with play. The gamification paradigm not only enhances user engagement but also catalyzes innovation, as engineers are encouraged to push the boundaries of conventional thinking and explore new avenues of problem-solving.
Building a Dream Team: The Datacurve Advantage
In the realm of AI development, success hinges not only on technological prowess but also on the collective expertise and passion of the individuals driving innovation forward. Recognizing this fundamental truth, Serena and Charley have spared no effort in assembling a dream team—a team endowed with the diverse skill sets, experiences, and perspectives necessary to tackle the most daunting challenges head-on. From seasoned industry veterans with years of hands-on experience to up-and-coming talent brimming with potential, Datacurve's roster of engineers represents a veritable melting pot of talent and creativity. United by their shared passion for innovation and problem-solving, they stand as a testament to the power of collaboration—a force capable of transcending boundaries, overcoming obstacles, and reshaping the future of AI.
Tailored Data for Diverse Applications
Datacurve's curated data sets cater to a wide spectrum of use cases, catering to the needs of both AI dev-tool startups and foundation model labs:
For AI Dev-Tool Startups: Datacurve offers meticulously curated data tailored to specific use cases, including UI design to React components generation, framework-specific code optimization, and repository-wide PR generation.
For Foundation Model Labs: The platform provides invaluable support in enhancing general model coding capabilities, offering data for tasks such as code refactoring for readability, performance optimization, and debugging assistance.
The Journey of Datacurve: From Vision to Reality
The trajectory of Datacurve from concept to reality is a testament to the unwavering dedication and entrepreneurial spirit of Serena and Charley. Their journey, marked by triumphs and setbacks alike, underscores the transformative potential of their vision for the future of LLM training.
Conclusion: Pioneering a New Frontier in AI
As Datacurve continues to push the boundaries of LLM training through its innovative approach to data curation, the possibilities for advancement in artificial intelligence are limitless. With a passionate team driving progress and a groundbreaking platform leading the charge, Datacurve stands poised to redefine the future of language model development, ushering in a new era of innovation and discovery.